

SideTables
本文由 简悦 SimpRead 转码, 原文地址 roadmap.isylar.com
NONPOINTER_ISA 这个设计思想跟 TaggetPointer 类似,ISA 其实并不单单是一个指针。
NONPOINTER_ISA 这个设计思想跟 TaggetPointer 类似,ISA 其实并不单单是一个指针。
arm64 架构 isa 占 64 位,苹果为了优化性能,存储类对象地址只用了 33 位,剩下的位用来存储一些其它信息,比如本文讨论的引用计数
其中一些位仍旧编码指向对象的类。但是实际上并不会使用所有的地址空间,Objective-C 运行时会使用这些额外的位去存储每个对象数据就像它的引用计数和是否它已经被弱引用。
查看 isa 的定义, 它里面定义了一个位域:ISA_BITFIELD,点击查看这个宏:
# if __arm64__
# define ISA_BITFIELD \
uintptr_t nonpointer : 1; \
uintptr_t has_assoc : 1; \
uintptr_t has_cxx_dtor : 1; \
uintptr_t shiftcls : 33; /*MACH_VM_MAX_ADDRESS 0x1000000000*/ \
uintptr_t magic : 6; \
uintptr_t weakly_referenced : 1; \
uintptr_t deallocating : 1; \
uintptr_t has_sidetable_rc : 1; \
uintptr_t extra_rc : 19
# elif __x86_64__
# define ISA_BITFIELD \
uintptr_t nonpointer : 1; \
uintptr_t has_assoc : 1; \
uintptr_t has_cxx_dtor : 1; \
uintptr_t shiftcls : 44; /*MACH_VM_MAX_ADDRESS 0x7fffffe00000*/ \
uintptr_t magic : 6; \
uintptr_t weakly_referenced : 1; \
uintptr_t deallocating : 1; \
uintptr_t has_sidetable_rc : 1; \
uintptr_t extra_rc : 8
可以看到,x86_64 和 arm64 下的位域定义是不一样的,不过都是占满了所有的 64 位(1+1+1+33+6+1+1+1+19 = 64,x86_64 同理),
union isa_t {
Class cls; ... (还有很多其他的成员,包括引用计数数量)
}
nonpointer:表示是否对 isa 开启指针优化 。0 代表是纯 isa 指针,1 代表除了地址外,还包含了类的一些信息、对象的引用计数等。 如果该实例对象启用了 Non-pointer,那么会对 isa 的其他成员赋值,否则只会对 cls 赋值。
是否关闭 Non-pointer 目前有这么几个判断条件,这些都可以在 runtime 源码 objc-runtime-new.m 中找到逻辑。
1:包含swift代码;
2:sdk版本低于10.11;
3:runtime读取image时发现这个image包含__objc_rawisa段;
4:开发者自己添加了OBJC_DISABLE_NONPOINTER_ISA=YES到环境变量中;
5:某些不能使用Non-pointer的类,GCD等;
6:父类关闭。
has_assoc:关联对象标志位
has_cxx_dtor:该对象是否有 C++ 或 Objc 的析构器,如果有析构函数,则需要做一些析构的逻辑处理,如果没有,则可以更快的释放对象
shiftcls:存在类指针的值,开启指针优化的情况下,arm64 位中有 33 位来存储类的指针
magic:判断当前对象是真的对象还是一段没有初始化的空间
weakly_referenced:是否被指向或者曾经指向一个 ARC 的弱变量,没有弱引用的对象释放的更快
deallocating:是否正在释放
has_sidetable_rc:当对象引用计数大于 10 时,则需要进位
extra_rc:表示该对象的引用计数值,实际上是引用计数减一。例如:如果引用计数为 10,那么 extra_rc 为 9。如果引用计数大于 10,则需要使用 has_sidetable_rc

那引用计数存在哪里呢?秘密就在extra_rc中。
extra_rc 只是存储了额外的引用计数,实际的引用计数计算公式:
引用计数=extra_rc+1。
extra_rc占了 19 位,可以存储的最大引用计数:2^{19}-1+1=524288,超过它就需要进位到SideTables。SideTables 是一个 Hash 表,根据对象地址可以找到对应的SideTable,SideTable内包含一个RefcountMap,根据对象地址取出其引用计数,类型是size_t。 它是一个unsigned long,最低两位是标志位,剩下的 62 位用来存储引用计数。我们可以计算出引用计数的理论最大值:2^{62+19}=2.417851639229258e24。
其实 isa 能存储的 524288 在日常开发已经完全够用了,为什么还要搞个 Side Table?我猜测是因为历史问题,以前 cpu 是 32 位的,isa 中能存储的引用计数就只有 2^{7}=128。因此在 arm64 下,引用计数通常是存储在 isa 中的。
引用计数存在哪?
Tagged Pointer不需要引用计数NONPOINTER ISA(isa 的第一位为 1) 的引用计数优先存在 isa 中 (extra_rc),大于 524288 了进位到Side Tables- 非
NONPOINTER ISA引用计数存在Side Tables
1:对象是否是Tagged Pointer对象;
2:对象是否启用了Non-pointer;
3:对象未启用Non-pointer。
满足 1 则不判断 2,依次类推。
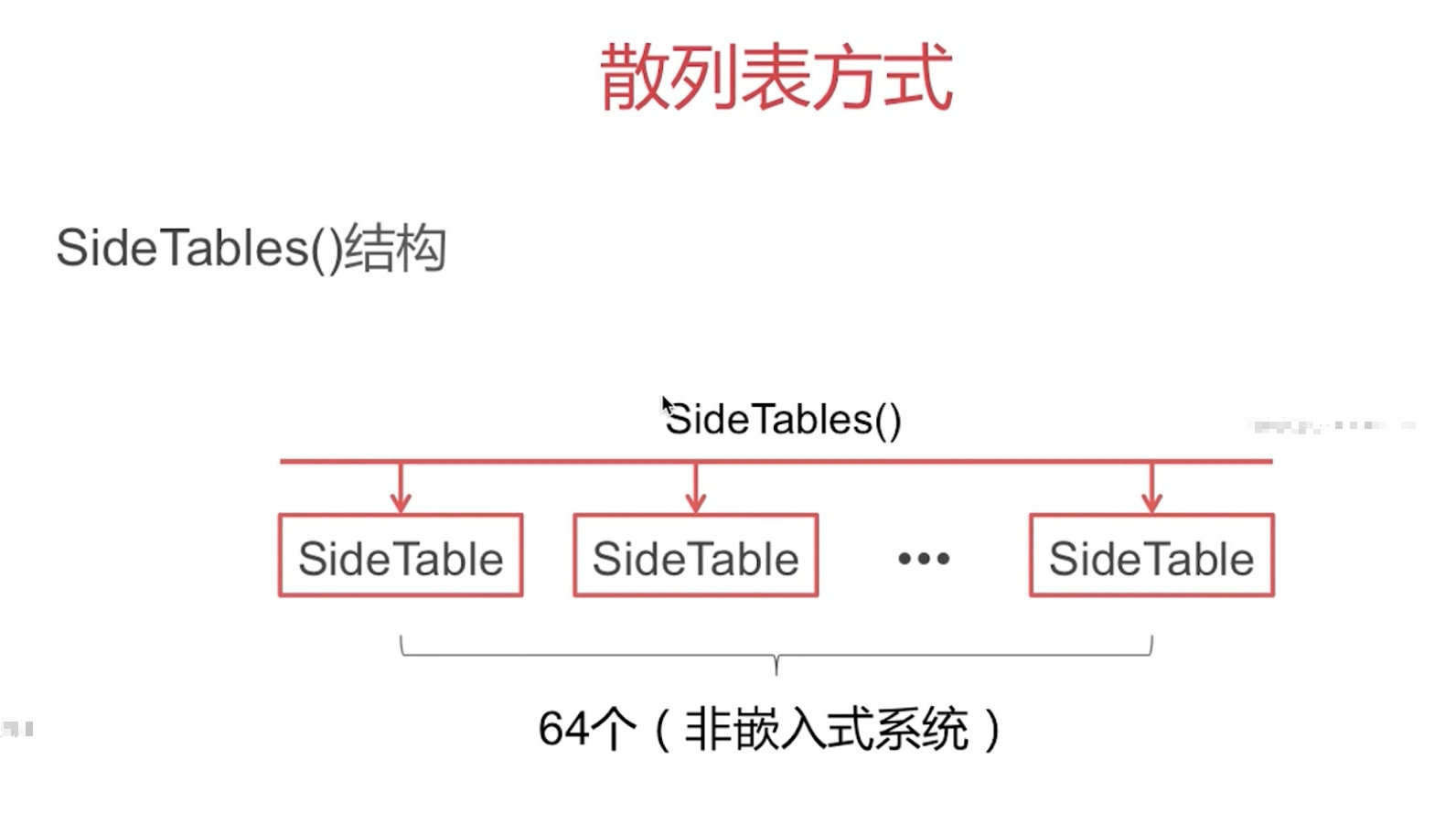
散列表 SideTables
在 runtime 内存空间中,SideTables 是一个 hash 数组,里面存储了 SideTable。SideTables 的 hash 键值就是一个对象 obj 的 address。 因此可以说,一个 obj,对应了一个 SideTable。但是一个 SideTable,会对应多个 obj。因为 SideTable 的数量有限,所以会有很多 obj 共用同一个 SideTable。
如果该对象不是 Tagged Pointer 且关闭了 Non-pointer,那该对象的引用计数就使用 SideTable 来存。
SideTables是一个 64 个元素长度 8 个元素长度 的 hash 数组,里面存储了SideTable。SideTables的 hash 键值就是一个对象obj的address。
value 包含了 引用计数与弱引用表
SideTable 的结构
struct SideTable {
spinlock_t slock; // 自旋锁
RefcountMap refcnts; //引用计数的Map表 key-value
weak_table_t weak_table; //弱引用表

如何从 sideTables 里找到特定的 sideTable 呢,这就用到了散列函数。runtime 是通过这么一个函数来获取到相应的 sideTable:
table = &SideTables()[obj];
static StripedMap<SideTable>& SideTables() {
return *reinterpret_cast<StripedMap<SideTable>*>(SideTableBuf);
}
template<typename T>
class StripedMap {
#if TARGET_OS_IPHONE && !TARGET_OS_SIMULATOR
enum { StripeCount = 8 }; // iPhone时这个值为8
#else
enum { StripeCount = 64 }; //否则为64
#endif
struct PaddedT {
T value alignas(CacheLineSize);
};
PaddedT array[StripeCount];
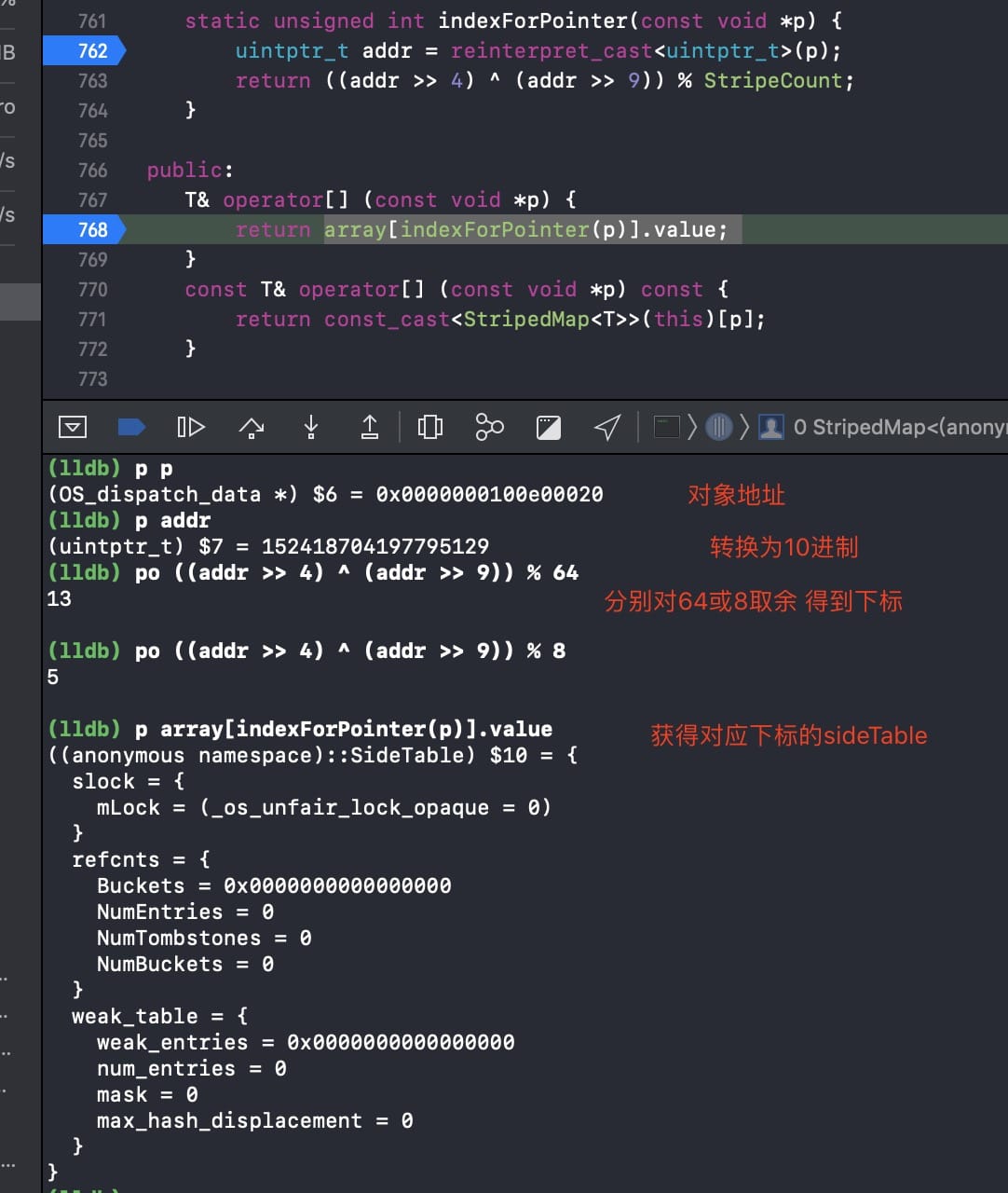
static unsigned int indexForPointer(const void *p) {
//这里是做类型转换
uintptr_t addr = reinterpret_cast<uintptr_t>(p);
//这就是哈希算法了
return ((addr >> 4) ^ (addr >> 9)) % StripeCount;
}
public:
T& operator[] (const void *p) {
//返回sideTable
return array[indexForPointer(p)].value;
}
可以看到,在对 StripeCount 取余后,所得到的值根据机器不同,会在 0-7 或者 0-63 之间,这就是通过哈希函数来获取到了 sideTable 的下标,然后再根据 value 取到所需的 sideTable。
执行 *table = &SideTables()[obj];* 之后,执行到了 _array[indexForPointer(p)].value;_,然后进行哈希算法获取到下标,再返回所需的 sideTable
为什么不直接用一张 SideTable,而是用 SideTables 去管理多个 SideTable?
SideTable 里有一个自旋锁,如果把所有的类都放在同一个 SideTable,有任何一个类有改动都会对整个 table 做操作,并且在操作一个类的同时,操作别的类会被锁住等待,这样会导致操作效率和查询效率都很低。而有多个 SideTable 的话,操作的都是单个 Table,并不会影响其他的 table,这就是分离锁。